
摘要
大意: 本文是 LLM Benchmarks: Overview, Limits and Model Comparison 的讀後筆記,這是與目前輪調在我家的 MA (跟這篇同一位呦)讀完後的討論心得。大型語言模型(LLM)的評估是人工智慧發展的關鍵,本篇的基準測試 (Benchmarks) ,包括各種關鍵性能評估、各模型比較、並帶到了基準測試的局限性,以及如何評估 AI 應用的未來潛力。
這篇文章分為多個部分,首先介紹了 LLM 基準測試的重要性,它提供了一種標準化的方法來評估語言模型在如寫程式、推理、數學、真實性、聊天機器人輔助、多模態和多語言等任務上的表現。接著,透過一個表格展示了在 2024 年 9 月 8 日時各大 LLM 模型在不同基準測試上的排名,其中包括前三名:Claude 3.5 Sonnet、GPT-4o、Meta Llama 3.1 405b 等模型的平均表現、多語言、工具使用、數學、推理、程式能力和整體性能(最新版本可以在此找到)。文章指出,Claude 3.5 Sonnet 在多項基準測試中表現最佳,尤其是在多語言、工具使用和程式能力方面。
主文筆記
導論:技術評估的哲學
在人工智慧快速發展的當代,基準測試已經不再是單純的技術指標,而是我們嘗試理解人工智慧模型能力的一種方法。就像人類的智力測驗試圖描繪個人的認知圖景,LLM 基準測試則企圖解析這些演算法大腦的運作邏輯。
主要評估面向:多維度能力解析
-
主流的 LLM 基準測試
- MMLU - 多任務準確性,在這裡測試為通用能力
- GPQA - 推理能力
- HumanEval - Python 程式碼能力
- MATH - 數學題目(含 7 個難度等級)
- BFCL - 函數/工具調用能力
- MGSM - 多語言能力

前三名模型在各基準測試上的表現
- 可以看得出來 Anthropic 的 Claude 3.5 Sonnet 在各項基準測試上平均表現最好,其次是 GPT-4o,最後是 Meta Llama 3.1 405b。Claude 3.5 Sonnet 在多項基準測試中都取得了最高分。在多語言能力(MGSM)方面達到了 91.60%,工具使用(BFCL)達到 90.20%,以及在程式碼能力(HumanEval)方面更是取得了令人印象深刻的 92.00%。它在數學(71.10%)和推理(59.40%)方面也表現優異,使其成為在各個關鍵類別中都表現出色的全能型選手。附帶一提,我也在用這個模型協助我 coding。
- Meta 的 Llama 3.1 405b 在多語言和通用基準測試中表現優異,這證明了開源模型既能提供優秀的性能,同時也具備更高的靈活性。儘管這些模型目前尚未廣泛開放使用,但我們可以明顯看到一個趨勢:開源模型的表現正逐漸接近頂級專有模型的水準(如果模型還能更小的話,我會更開心)。
-
認知推理與理解能力
- 常識性推理:ARC 和 HellaSwag 基準測試模擬日常生活中的推理情境,評估模型是否具備類似人類的直覺思考能力。這些測試不僅檢驗邏輯,更挑戰模型理解隱含意義的能力。簡單以 HellaSwag 來說,它檢測模型是否能基於常識完成句子,從四個選項中選擇出正確的答案。在 2024 年為止, GPT-4 的表現為最好,準確率最高達到 95.3%。
- 閱讀理解:DROP 基準如同一場智力競技,要求模型從複雜文件中提取關鍵訊息,並進行深度推理。這考驗的不僅是資訊擷取,更是對上下文的精準理解。但在 2023 年 12 月, Hugging Face 發現 DROP 基準測試存在問題,導致許多模型在 DROP 測試中表現不佳。
- 多學科智能:MMLU(Massive Multitask Language Understanding)與 TruthfulQA 基準橫跨數學、歷史、計算機科學等領域,宛如一場全方位的知識競賽,測量模型知識的廣度與深度。
-
數學
- 有句話是這麼說的:「數學不會背叛你,因為數學不會就是不會。」
- MATH 基準測試包含 12,500 個競賽級數學問題,測量模型在數學領域的表現。
- GSM8K 基準測試則是 8.5K 小學數學問題,這些問題需要 2 到 8 個步驟來解決,解答過程主要涉及使用基本算術運算(+、-、/、*)的一系列計算步驟來得出最終答案。一名聰明的中學生應該能解出所有問題。
-
實務技術能力
- 程式碼生成:HumanEval 和 MBPP 基準可視為程式設計的圖靈測試。它們不僅檢驗模型撰寫程式碼的能力,更評估其理解程式邏輯和解決問題的技巧。
- 工具操作:BFCL (Berkeley Function Calling Leaderboard) 與 MetaTool 模擬真實工作場景,測試模型靈活運用各種工具的能力。這彷彿是檢驗一個 AI 代理人的實務勝任度。
- 多模態理解:MMMU (Multimodal Model Understanding) 基準挑戰模型整合視覺和文字訊息的能力,猶如考驗人腦同時處理不同感官(聽、讀、看)輸入的複雜機制。
-
對話與聊天互動
- 聊天機器人評估:Chatbot Arena 和 MT-bench 模擬真實對話情境,不僅測量回應的技術準確性,更評估模型在語境中的靈活性和自然度。前者為 crowdsourcing 的評估,也就是讓人去投票兩個答案誰比較好;後者則是使用 LLM 作為評審。
- 多語言能力:MGSM (Multilingual Grade School Math) 基準測試檢驗模型在不同語言中的文字理解能力,這裡再度拿了 GSM8K 的數學題目,反映了我前面寫的那段話:「數學不會背叛你,因為數學不會就是不會。」
模型版圖:領先者與新秀
- 頂尖模型:Claude 3.5 Sonnet、GPT-4o、Meta Llama 3.1。但以最新的資料,可以看出來 GPT-1o 可能更有達到神級境界的能力。
- 開源模型的崛起:Llama 3.1 在多語言和通用能力測試中的出色表現,代表開源模型在未來的潛力。
- 差異化能力:每個模型在不同測試中展現獨特優勢,如同人類的個人特長,要說哪個模型最好,這個問題其實很難回答,因為每個模型都有自己的優勢和局限性;另一方面,模型的更新速度很快,所以這個排名很快就會過時。
基準測試的未來:局限與可能
現有的 LLM 基準測試存在兩大根本挑戰:
- 範圍的侷限性:許多基準測試的範圍受限,通常只針對 LLM 已展現一定能力的領域進行評估。由於這些測試集中在模型擅長的範疇,因此無法有效發現模型在進一步發展中可能出現的新技能或意外能力。就像我們不會用一次考試斷定一個人的全部潛力。雖然說,至少還算是公平的……。
- 生命週期短暫:語言模型基準測試的實用性通常維持不了太久。一旦語言模型在這些基準測試中的表現達到與人類相當的水準,這些測試通常就會被停止(例如 ImageNet )、替換,或透過加入更高難度的挑戰進行更新。這種生命週期短暫,難以進行長期追蹤的情況,可能是因為這些基準測試未涵蓋比當前語言模型能力更高難度的任務。
BIG-bench:探索未來的試金石
BIG-bench (Beyond the Imitation Game Benchmark) 代表了一種更具前瞻性的評估嘗試,致力於預測和測量語言模型的當前和未來能力。它不僅關注模型現有的表現,更試圖窺探人工智慧可能的發展軌跡。
- 🧠 BIG-bench 測試語言模型的當前與未來能力和限制。
- 📈 目的是了解模型改善後能力和限制的變化方式。
- 📚 評估包括超過 200 項任務,被認為超出當前語言模型能力。
- 👥 由 450 位作者來自 132 家機構貢獻。
- 🌍 涵蓋主題多樣,包括語言學、童年發展、數學、常識推理、生物學、物理學、社會偏見、軟體開發等。
SOTA leaderboard
我們看到這篇文章時的發表時間 是 2024 年 9 月 11 日,但文末提到的 llm leaderboard 是三月的。先節錄一下文末的內容:
- In summary, at the time of writing this blog post (March 2024), the TL;DR of this leaderboard indicates:
- Claude 3 Opus has the best average score across all benchmarks, and Gemini 1.5 Pro is right after (although this model isn’t yet released);
- GPT-4 is starting to fall behind Gemini and Claude models (I guess we’re waiting for GPT-5);
- Claude 3 Sonnet and Haiku are showing better results than GPT-3.5 (they’re in the same category of cheaper and faster models);
- Mixtral 8x7B is the open-source model that has best average scores across all benchmarks for open source models;
若是用最新的版本,也就是 2024 年 12 月 18 日的版本,我們來試著改寫:
-
截至2024年12月18日的最新資料顯示,LLM排行榜有以下更新:
- Claude 3.5 Sonnet:在多項基準測試中表現最佳,平均得分為 82.10%,在多語言(91.60%)、工具使用(90.20%)和程式碼生成(92.00%)等領域均名列前茅。
- GPT-4o:在數學(76.60%)和推理(53.60%)方面表現突出,總體平均得分為 80.53%,僅次於 Claude 3.5 Sonnet。
- Meta Llama 3.1 405b:作為開源模型的代表,平均得分達 80.43%,在多語言和工具使用方面與頂級專有模型競爭激烈。
- GPT-Turbo:平均得分為 78.12%,在各項測試中表現穩定。
- Claude 3 Opus:平均得分為 76.70%,在多語言和工具使用方面表現優異。
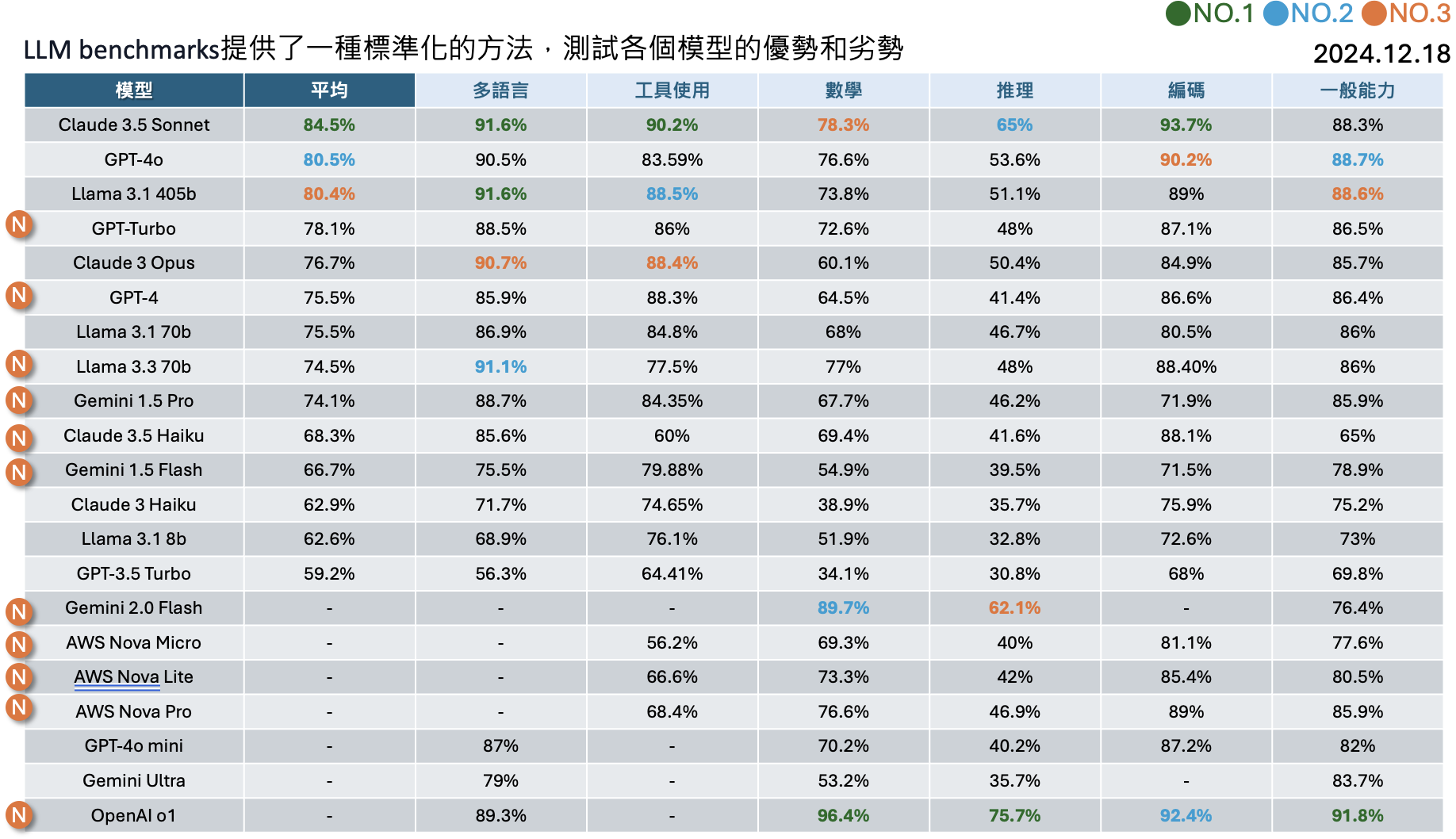
2024-12-18 最新版本
結論
基準測試如同一面鏡子,反映了模型的當下,卻難以窺見未來
LLM 基準測試是理解 AI 模型能力的重要機制。隨著技術發展,我們需要不斷完善評估方法,以更準確地衡量模型表現。
個人省思
模型規模大或小?
- 技術評估從來不只是數字遊戲。就像人類的能力難以被單一測驗定義,AI 模型也是如此。每一個基準測試都提供了一個思考面向,但真正的智慧在於靈活運用和處理未知情境的能力。目前(真的是目前,再過半年不敢講了)應該還沒有什麼基準測試能夠測試出模型在未知情境下的表現。
- 目前的大語言模型(如 GPT-4、Claude 3.5)持續增大規模,更多參數通常意味著更高的表現力。然而,規模並非唯一的成功因素,專業化和針對性訓練逐漸成為關鍵。例如:
- 專業模型(如醫療、法律、金融領域)能針對特定應用場景進行微調,比通用型模型更具優勢。
- 多模態模型(如文字與影像結合)將是下一個重要趨勢,使模型能夠理解和生成跨領域的資訊。
- 未來的進化可能會朝向 “小而精” 和 “大而全” 並行發展的方向,滿足不同使用需求。
垂直應用的價值
- 呈上所述,垂直應用將會是未來的趨勢,而垂直應用的價值在於能夠針對特定領域進行微調,比通用型模型更具優勢。
- 大語言模型不僅停留在生成文字上,還開始結合工具,如程式碼生成、資料分析、客戶服務等。例如,OpenAI 的 Codex 專注於程式設計任務(但模型變化太快了,時至今日我比較推 Claude 3.5 Sonnet XD)。這些模型的 工具化與實用化 提升了生產力,進一步融入各行各業。未來模型的重點可能會放在:
- 與現有工作流整合(如與 ERP 或 CRM 系統對接)。
- 自動化更多知識密集型任務(如法律文書生成、醫療診斷輔助)。
未來發展
- 大語言模型未來可能朝向以下方向發展:
- 更高的效率:透過壓縮模型大小(如 LoRA 等量化技術)以降低運算成本,增加可用性。
- 即時更新能力:模型可能會實現更快的知識更新,縮短從數據到實用的時間週期。
- 更多人機互動的自然性:結合情感分析、記憶機制等,讓 AI 能與人類進行更長期且具智慧的智能交互。
- (這篇其實沒有提到,但是勢必要有的)法律與倫理框架的成熟:AI 治理將成為不可忽視的話題,不論在國外還是台灣,都已經有進行中或剛開始的法規制定。
心得
在這個快速變遷的 AI 世界中,保持好奇、保持開放,或許是最重要的基準測試。大語言模型的演進是一場技術和應用的賽跑。它不僅在深度學習的框架下改變了生產力工具,也在挑戰著我們對技術的知識邊界和社會影響的認知。這場革命最終將如何形塑未來,取決於我們能否以負責任且創新的方式引導其發展。
Note
- 這篇文章沒有討論任何有關 DeepSeek 的模型,但從最近的新聞可以看到這家中國新創推出的模型,在多項基準測試中表現優異,以驚人的低成本和高效率,在性能上與 OpenAI 的 GPT-4o 相媲美。
參考資料 (AI 生成)
- LLM Benchmarks: Overview, Limits and Model Comparison
- LLM Leaderboard
- BIG-bench
- Chatbot Arena
- MT-bench
- Hugging Face
- Open-LLM Leaderboard
- Open-LLM Leaderboard Drop