上週以 LINE API Expert 的身份參加了今年於東京台場舉辦的 LINE Developer Day 活動。其中有一場硬底子的分享我覺得蠻值得一提的,簡單一句就是用 Hadoop 在上層做 Cluster Federation ,總共管理了超過二千個節點。

之所以講硬底子,因為 LINE 工程師在進行這個擴展/遷移節點的過程中,遇到的問題有送 upstream patch 回原本的專案 repo (簡單列一下投影片有提到的,照看起來應該還有不少):
- Webhdfs backward compatibility (HDFS-14466 reported by LINER)
- Support Hive metastore impersonation(Presto#1441 by LINER)
- File Merge tasks fail when containers are reused (HIVE-22373 by LINER)

幾年前還「只不過」是一個即時通訊軟體的 LINE 。時至今日,LINE 本身的服務量已經是愈來愈大了,開始嘗試提供各式各樣的服務,想當然而所有的資料格式欄位(以 SQL 的角度來看)各有不同。

看起來很棒,實際上對於 Data Platform 部門的工程師則不然,如果羅馬不是一天造成的,這些服務與資料並不是同時打造好提供給大家使用的,這是日積月累的使用記錄,加上服務系統迭代更新後,產生的資料。可以參考去年的演講,那時候的資料看起來還沒有這次的一半多。所以理想與現實的差距,造就了 10 座以上的 HDFS Clusters ,在系統維護與軟體更新上都拉大了難度與時間。各個 Cluster 的版本不一,能提供的 API 以及工具也無法統一。最後工程師們決定整頓一下,一統公司內的 Hadoop 江湖(想想一次可以送 job 在 2k+ node 上跑,想到就…..)

當然改變不是一蹴而就,當年(應該是每年)留下來技術債也是要還的(OS: 砍掉重練就不用了…),工程師們決定邊開飛機邊改引擎 (…)。所以定了幾個 Criteria ,包括 Minimum Downtime、Incremental Migration 以及最重要的 High Security Level/Minimum Risk 。
講者簡介了幾種他們一開始規劃的想法,比如建一個新的,然後把所有的資料往裡面搬。這個當然是一個理想但不實際的方法,除非你不在意 downtime 、不在意相容性、不在意因此要多買一倍的儲存空間。另一個進階的想法則是把最大的 cluster 再擴大,然後把其他的 cluster 整合進去,這個遇到的問題是實務面的:最大的 cluster 沒有使用 Kerberos;有兩個非常大的 cluster 是有頻繁的用戶存取的;整合完, Hadoop 還是需要再更新。最後方法就採用了 HDFS Federation 架構來解決這個問題,基本上利用 HDFS Federation 可以有 multi-namespace 的特點,來支援後續的 data/service migration 。
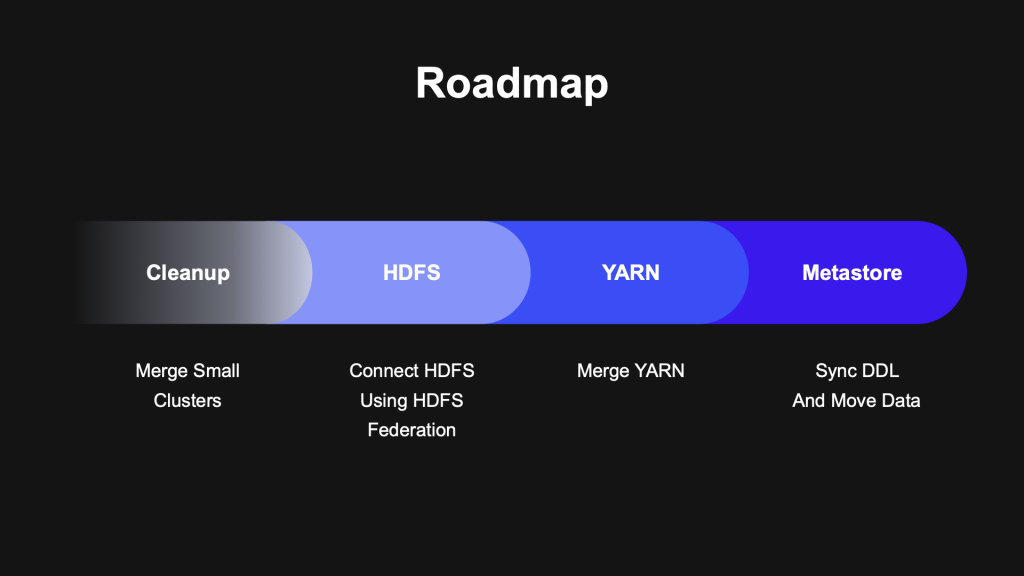
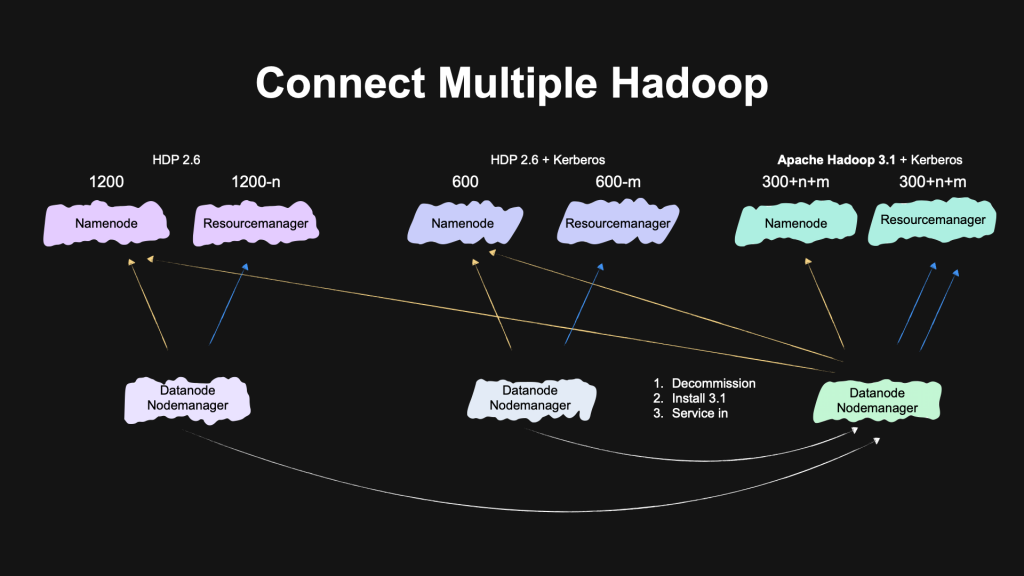
但即使如此,在實作上還是運到了一些問題,有經驗的工程師聽到這裡大概也可以猜出來,各 cluster 原始的版本相容性會直接地影響到 merge 的成果,在這中間的過程中踩了不少雷,也因此提出 patch 增強(或修正) upstream 原有的功能。而這些的修改,都是在一邊更新 cluster 並作適度的 ETL 時,同時間也能讓原有的系統能夠持續運作,我想這點要對 Data Platform Dept. 的工程師及架構師們致敬。
最後放上一張我認為很能代表這場演講的投影片。